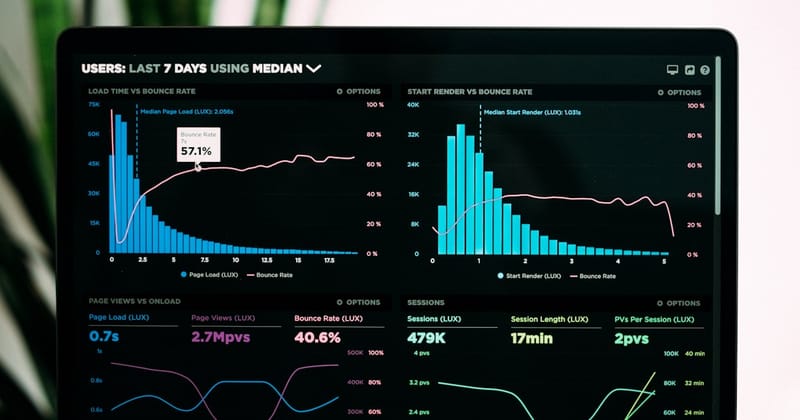
From Homebrew 6.0.0 to a Reliable Prometheus + Grafana Stack: A Practical Homelab Guide
A practical deep dive into monitoring stack: Prometheus and Grafana setup — real examples, comparisons, and setup guides.
From Homebrew 6.0.0 to a Reliable Prometheus + Grafana Stack: A Practical Homelab Guide
Homebrew 6.0.0 just dropped, and it’s not just a unicorn of package managers. It’s a signal: the tooling to bootstrap a reliable, repeatable monitoring stack in a home lab is maturing enough that a curious hobbyist can set up Prometheus, Grafana, and friends without fighting package hell. If you’re like me, you want to sleep better on Saturdays—knowing your services are being watched, not just hoping nothing breaks. This article ties that news thread to a practical Prometheus + Grafana setup you can use today, with concrete commands, a working docker-compose example, and an honest look at what changes you actually need to make to stay sane as your stack grows.
Why this matters now (and how the news ties in)
The Homebrew 6.0.0 release is the kind of signal that makes it reasonable to put tooling in a single, repeatable place. For a homelab, that translates into:
- Easier onboarding of monitoring components on macOS hosts or lightweight VMs.
- A more predictable upgrade path for Prometheus, Grafana, and related exporters.
- Fewer fights with dependencies when you’re juggling multiple lab projects (k8s clusters, local apps, NAS-backed storage).
There’s more to the story than packaging. The broader open-source ecosystem around observability is converging on practical, integrated stacks. The MiMo Code release from Xiaomi is a reminder that the barrier to contributing and tweaking monitoring tooling is lower than ever. That spirit—open tooling that you can run, modify, and extend—fits right into a homelab where you’re testing alerts, dashboards, and long-term storage strategies. And yes, the “humans in the loop” problem remains real: you need sane alerting, runbooks, and escalation paths so your monitoring doesn’t become noise.
I’m not arguing for buying a black-box SaaS all-in-one. If you want control, speed, and the ability to tinker at 2 a.m., Prometheus + Grafana on a modest node is still the gold standard. Let me show you how I’ve wired it up, in a way that scales to a small home cluster or a single dedicated server.
The stack: what you’re building and why
At the core, you’ll want:
- Prometheus: the time-series database and query engine. It scrapes metrics from exporters and stores them locally for fast dashboards and alerting.
- Grafana: the visualization layer. It’s how you see health, not just data in a table.
- Exporters (node_exporter, blackbox_exporter, and optionally cadvisor or mysqld_exporter, etc.): the data sources Prometheus scrapes.
- Alertmanager: the alert routing and deduping brain for Prometheus alerts.
- Optional long-term storage or multi-cluster querying: Thanos or VictoriaMetrics for scaling, retention, and cross-cluster dashboards. This is where the “Don’t rely on localhost Prometheus forever” mindset matters.
A simple, practical homelab architecture
- One or more Linux hosts (or VMs) running node_exporter, blackbox_exporter, and your app exporters.
- A Prometheus server that scrapes the exporters and stores time-series data.
- Alertmanager for alert routing to your preferred channels (Slack, email, Pushover, PagerDuty, etc.).
- Grafana for dashboards and alert visualization.
- Optional: Loki for logs, Tempo for traces, if you’re aiming for a full observability stack.
A quick, hands-on setup you can run today (Docker Compose)
If you want a fast start, a docker-compose-based setup is the fastest path to a working stack. It gives you Prometheus, Alertmanager, Node Exporter, and Grafana in one place, with a sane default configuration. Save this as docker-compose.yml, then bring it up and you’re in business.
docker-compose.yml
version: '3.8'
services:
prometheus:
image: prom/prometheus: latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
ports:
- "9090:9090"
restart: unless-stopped
alertmanager:
image: prom/alertmanager:latest
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
- alertmanager_data:/data
ports:
- "9093:9093"
restart: unless-stopped
grafana:
image: grafana/grafana:latest
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
depends_on:
- prometheus
ports:
- "3000:3000"
restart: unless-stopped
node-exporter:
image: prom/node-exporter:latest
ports:
- "9100:9100"
restart: unless-stopped
# If you run this inside docker-compose on Linux, you can share the host net
# or use a dedicated network. Here we expose 9100 for simplicity.
volumes:
prometheus_data:
alertmanager_data:
prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node-exporter'
static_configs:- targets: ['node-exporter:9100']
rule_files:
- 'alerts.rules.yml'
alerts.rules.yml (example)
groups:
- name: host
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "No scrape data from {{ $labels.job }} since {{ $labels.instance }}"
alertmanager.yml (simple route)
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'null'
receivers:
- name: 'null'
email_configs:
- to: 'you@example.com'
from: 'alertmanager@example.com'
smarthost: 'smtp.example.com:587'
auth_username: 'alertmanager@example.com'
auth_identity: 'Alertmanager'
auth_password: 'password'
Notes:
- This is a starting point. You’ll want to customize alert routing to your real channels (Slack, PagerDuty, SMS, etc.).
- For a macOS host, you can run Prometheus and Grafana locally with data directories mounted to keep state across restarts.
Installing via Homebrew (for Mac users)
If you’re doing this on a Mac, Homebrew 6.0.0 makes it nice and predictable to pull in Prometheus and Grafana for dev/test runs or home lab tinkering. Quick-start steps:
- Install the packages:
brew install prometheus grafana - Start the services (macOS uses launchctl via brew services):
brew services start prometheus
brew services start grafana - Access Grafana at http://localhost:3000 and log in with admin/admin (you’ll be prompted to change the password).
- Create a folder with your prometheus.yml and the alerting rules, then point Prometheus to that file path:
# Example path, adjust as needed
# /usr/local/etc/prometheus/prometheus.yml (where brew stores config) - In Grafana, add Prometheus as a data source (http://localhost:9090) and import dashboards.
If you want more reliability than “just run Prometheus in a local Mac,” I recommend splitting responsibilities: run Prometheus and Alertmanager in containers or VMs in your homelab, and use a separate Grafana instance to visualize dashboards. The point is to have repeatable setups you can script, and Homebrew 6.0.0 makes that part less painful on macOS.
Two paths for scale: self-hosted vs scale-out (with a nod to recent news)
Self-hosted Prometheus + Grafana is perfect for a single server or a small homelab. But once your data grows or you want cross-cluster dashboards, you’ll want a scaling strategy. Here are two common paths:
- Self-hosted with long-term storage: Prometheus + Thanos or Cortex
- Pros: you get global query across clusters, deduplication, and long-term storage in object storage.
- Cons: more moving parts, more operational complexity.
- What you’ll do: deploy Thanos sidecars or Cortex components, configure remote_write/remote_read, and set up a bucket in S3/GCS.
- VictoriaMetrics as a drop-in Prometheus-compatible backend
- Pros: easier to deploy than a full Thanos stack in some cases, better compression, supports PromQL-compatible API.
- Cons: ecosystem dashboards and docs sometimes lag a bit behind pure Prometheus, but that gap is narrowing.
- What you’ll do: run VictoriaMetrics as a remote storage backend for Prometheus or use it as a standalone time-series database with Prometheus scraping.
Comparison table: Prometheus + Grafana options at a glance
| Option | Setup Complexity | Scaling / Long-term storage | Data model compatibility | When to choose |
|---|---|---|---|---|
| Self-hosted Prometheus + Grafana (default) | Low to moderate (docker-compose, simple VMs) | Limited to local storage; can add remote write | Full PromQL, best for small labs | Simple, cheap, quick dashboards; single node or small cluster |
| Prometheus + Thanos (or Cortex) | Moderate to high | Excellent cross-cluster and long-term storage | Full PromQL with global view | Multi-cluster, long retention, strict SLA monitoring |
| VictoriaMetrics (as backend) | Moderate | Good compression, scalable | PromQL-compatible, fast queries | Easier scaling than vanilla Prometheus in many setups |
| Managed Prometheus / Grafana Cloud | Low upfront, ongoing cost | Handled by provider | Same PromQL, plus provider features | You want minimal ops, not hosting the stack yourself |
What changed, and what to do next
- Exporters and dashboards now tick along more reliably with modern packaging. If you’re upgrading from an older Prometheus/Grafana setup, plan a migration window: export your dashboards and alerting rules, test them on a staging Prometheus, and then roll out to production.
- Long-term storage decisions are no longer optional for homelabs that are serious about reliability. If you’re just starting out, you can stay on local Prometheus for 3–6 months while you pilot Thanos or VictoriaMetrics on a separate node.
- Alerting discipline matters. The “If you are asking for human attention, demonstrate human effort” ethos applies here too. Define clear alert rules, use grouping, set meaningful for durations, and wire up a sensible runbook. If your on-call team is you, write the runbook like you’d want to find it at 2 a.m.
- Open-source tooling continues to be accessible. The MiMo Code release is a reminder that you don’t need corporate-grade budgets to run meaningful observability. You can build, contribute, and extend dashboards that actually help you sleep at night.
A practical, real-world workflow you can replicate
1) Build a repeatable baseline with Docker Compose (as shown above). This gives you a known-good starting point to test dashboards and alerts locally before pushing to a remote host or cluster.
2) Add node_exporter to your hosts for granular OS metrics:
- On each host: docker run --name node-exporter -p 9100:9100 prom/node-exporter:latest
3) Create a simple alert for host availability:
- In alerts.rules.yml, add an InstanceDown rule (as shown in the docker-compose example).
4) Import dashboards in Grafana:
- In Grafana, add a data source Prometheus at http://prometheus:9090.
- Use Import and search for Node Exporter dashboards (or import a couple of pre-built dashboards you find on Grafana.com, e.g., Node Exporter Full).
5) Expand gradually:
- Add blackbox_exporter to monitor endpoints behind firewalls or NATs.
- If you’re running containers with Kubernetes, switch to kube-prometheus-stack or a customized Helm chart to get richer metrics quickly.
A practical example you can copy-paste (Prometheus + Grafana basics)
Here’s a minimal, working Prometheus scrape target and alert rule you can try in your Docker Compose setup. Save these in your repo under the same directory as docker-compose.yml.
prometheus.yml (minimal)
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node-exporter'
static_configs:- targets: ['node-exporter:9100']
alerts.rules.yml (example)
groups:
- name: host
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "No scrape data from {{ $labels.job }} since {{ $labels.instance }}"
alertmanager.yml (basic, route everything to null for local testing)
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: 'null'
email_configs:
- to: 'you@example.com'
from: 'alertmanager@example.com'
smarthost: 'smtp.example.com:587'
auth_username: 'alertmanager@example.com'
auth_identity: 'Alertmanager'
auth_password: 'password'
This is deliberately simple. In practice, you’ll route alerts to Slack, Teams, PagerDuty, or your on-call channel, and you’ll refine the thresholds.
A note on dashboards and data fidelity
- Start with a Node Exporter full dashboard to understand baseline OS metrics (CPU, memory, disk, network). Import a second dashboard for your application (if you have one) or a general Kubernetes dashboard if you’re running a cluster.
- Grafana’s dashboard provisioning (via JSON or YAML) helps keep dashboards in version control. If you’re serious about repeatability, treat dashboards like code: store them in Git, and use Grafana’s API or provisioning to deploy them.
What to do next, concretely
- If you’re new to Prometheus + Grafana, pick the docker-compose path and get a functioning stack up this week. Then, pick one export source (node_exporter) and one dashboard to master.
- If you’re already running a stack, audit your alert rules. Remove noisy alerts, set appropriate for durations, and verify that your alert routing actually reaches you in a timely way.
- If you’re feeling ambitious, try Thanos or VictoriaMetrics as a long-term storage backend. It’s not magic, but it scales a lot better than a single Prometheus instance as you accumulate months of data.
A short, actionable conclusion
Homebrew 6.0.0’s arrival isn’t a silver bullet, but it’s a nudge toward repeatable, open-source tooling for monitoring your homelab. Start with Prometheus + Grafana in a docker-compose setup, bolt on a couple of exporters, and define a few sane alerts. Then decide if you want to add long-term storage with Thanos or VictoriaMetrics. The goal is to have dashboards that reflect reality, alerts you can act on, and a stack you can rebuild in under an hour if something goes wrong.
If you take one practical step this week, do this:
- Spin up the docker-compose-based stack (Prometheus, Alertmanager, Node Exporter, Grafana), then import a Node Exporter dashboard and create one alert (InstanceDown) for your hosts. Put the config in Git, and test a simulated outage to confirm alerts reach you as expected.
That tiny, repeatable loop—build, observe, adjust—will outpace the random outages that keep you up at night. And if you’re curious about where the ecosystem is heading, keep an eye on how open tooling, like MiMo Code and similar projects, continues to lower barriers. Your homelab deserves this kind of discipline: a monitoring stack that’s boring in operation and precise in alerting.